RunModel
RunModel is the core module for UQpy to execute computational models
RunModel contains a single class, also called RunModel that is used to execute computational models at specified
sample points. RunModel may be used to execute Python models or third-party software models and is capable of
running models serially or in parallel on both local machines or HPC clusters.
The module currently contains the following classes:
RunModel: Class for execution of a computational model
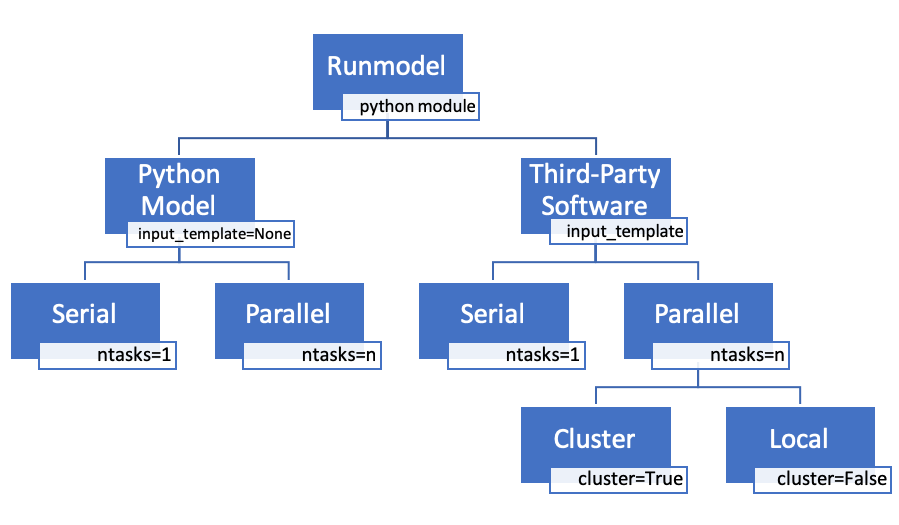
Architecture & Workflow
The RunModel class has four basic workflows delineated in two levels. At the first level, RunModel can be used
for execution of either a Python computational model, in which case the model is imported and run directly, or for
execution of a third-party software model. When running with a third-party software model, RunModel interfaces with
the model through text-based input files and serves as the “driver” to initiate the necessary calculations. At the
second level, the jobs that are run by RunModel can either be executed
in series or in parallel. In the following sections the workflow is discussed in detail.
Python Model Workflow: Serial Execution
A common workflow in UQpy is when the computational model being evaluated is written in Python. This workflow is
invoked by calling RunModel using a PythonModel without specifying an input_template (i.e. input_template = None) and setting
model_script to the user-defined Python script containing the model. This python model is run serially by setting
ntasks = 1.
UQpy imports the model_script and executes the object defined by model_object_name. The
model_object can be structured such that it accepts one sample at a time or accepts an array/list of samples all at
once. The model_object may be a class or a function. If the model_object is a class, the quantity of interest
must be stored as an attribute of the class called qoi. If the model object is a function, it must return the
quantity of interest after execution.
Details for model_script can be found in the Section entitled Files & Scripts Used by RunModel.
Python Model Workflow: Parallel Execution
The python model is executed in parallel by setting ntasks equal to the desired number of tasks (greater than 1) to be executed concurrently. In this
case, the model_script and corresponding model_object should be defined to accept a single sample. RunModel uses the mpi4py library for
parallel execution of python models. OpenMPI library is essential for mpi4py
and must be installed on the computer running the model. Information regarding how to install OpenMPI is provided
at https://www.open-mpi.org/faq/?category=building.
Details for model_script can be found in the Section entitled Files & Scripts Used by RunModel.
Third-Party Model Workflow: Serial Execution
The RunModel class also supports running models using third-party software. This worrkflow uses a text-based template input file, input_template, to pass
information from UQpy to the third-party model, and a Python script output_script to process the outputs and collect the results for post-processing.
This workflow operates in three steps as explained in the following:
UQpytakes the fileinput_templateand generates an indexed set of input files, one for each set of sample values passed through thesamplesinput. For example, if the name of the template input file isinput.inp, thenUQpygenerates indexed input files by appending the sample number between the filename and extension, asinput_1.inp,input_2.inp, … ,input_n.inp, wherenis the number of sample sets insamples. The details of how theinput_templateshould be structured are discussed in the Section entitled Files & Scripts Used by RunModel. During serial execution, one input file is generated, the model is executed, another input file is generated, the model is executed, and so on.The third-party software model is executed for each set of sample values using the indexed model input file generated in Step 1 by calling the Python script specified in
model_scriptand passing the sample index. This can be done either serially (which may be performed by settingntasks = 1) or in parallel over multiple processors (by settingntask > 1).For each simulation, the third-party model generates some set of outputs in Step 2. The user-defined
output_scriptis used to post-process these outputs and return them toRunModelin a list form, defined as an attribute ofRunModelcalledqoi_list. This script should extract any desired quantity of interest from the generated output files, again using the sample index to link model outputs to their respective sample sets.UQpyimports theoutput_scriptand executes the object defined byoutput_object_name. The structure of theoutput_objectmust be such that it accepts, as input, the sample index. If theoutput_objectis a Class, the quantity of interest must be stored as an attribute of the class calledqoi. If theoutput_objectit is a function, it must return the quantity of interest after execution. More details specifying the structure ofoutput_scriptand the associatedoutput_objectcan be found in the Section entitled Files & Scripts Used by RunModel. Finally, becauseUQpyimports theoutput_scriptand executes it withinRunModel, the values returned by the output object are directly stored according to their sample index in theRunModelattributeqoi_list.
Third-Party Model Workflow: Parallel Execution
Parallel execution in RunModel is carried out by the mpi4py library. OpenMPI library is essential for mpi4py
and must be installed on the computer running the model. Information regarding how to install OpenMPI is provided
at https://www.open-mpi.org/faq/?category=building. Parallel execution is activated in
RunModel by setting the parameter ntasks>1. The key differences in terms of the workflow are listed below.
During parallel execution, the execution of different samples is distributed among the different tasks and required input files are generated individually prior to each run. individually prior to each run.
OpenMPI divides the total number of jobs into a number of chunks specified by the variable
ntasks.ntasksnumber of jobs are executed in parallel and this continues until all the jobs finish executing. This is specified by settingcores_per_taskandnodesappropriately. Details can be found in the description of theRunModel. Whether in serial or parallel, the sample index is used byRunModelto keep track of model execution and to link the samples to their corresponding outputs.RunModelachieves this by consistently naming all the input files using the sample index (see Step 1) and passing the sample index intomodel_script. More details on the precise structure ofmodel_scriptare discussed in the Section entitled Files & Scripts Used by RunModel.Output processing in the parallel case is performed after every individual run.
Parallel Cluster Execution
The RunModel class also supports launching jobs in parallel on HPC clusters. The setup for this execution model is the same for both the Python and
third-party model workflows; however, the user is also able to provide a cluster-specific script that launches the most computationally intensive portions
of the simulation using cluster and scheduler specific commands. The pre- and post-processing can be done outside of this cluster-specific portion of the workflow. In order to enable cluster execution, RunModel must be configured as follows:
The execution mode most be configured to parallel by setting any or all of
ntasks,cores_per_task, ornodesto a value greater than 1.The
RunTypemust be input asCLUSTERThe user must provide the
cluster_scriptinput
With this configuration, RunModel will launch the computationally intensive portion of the workflow as specified in the cluster_script. The cores_per_task, n_new_simulations, and n_existing_simulations are passed as command line arguments to
the cluster_script when it is launched, so it is the user’s responsibility to use these inputs in the provided cluster script to configure the simulations for the specific HPC cluster and scheduler setup.
Directory Structure During Third-Party Model Evaluation
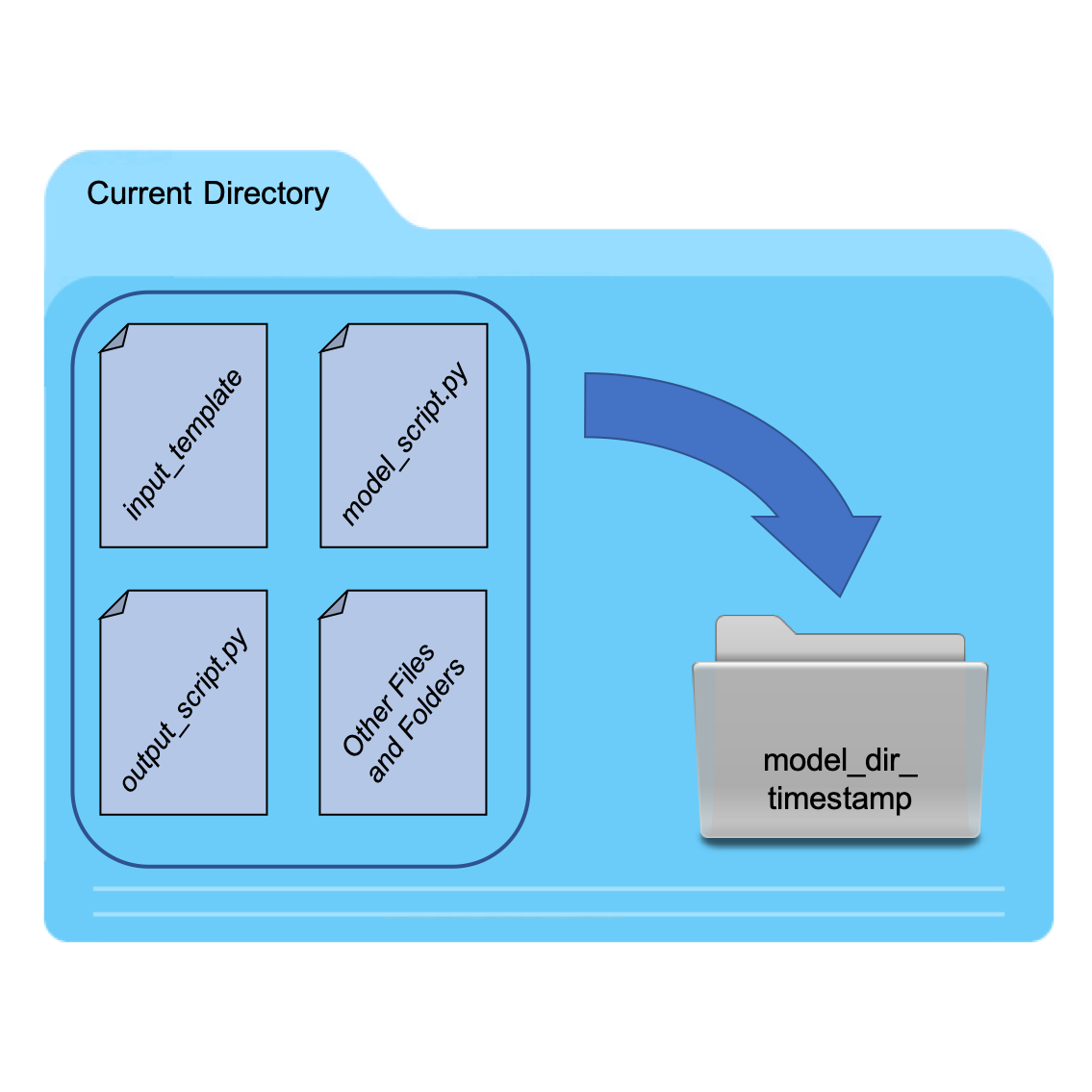
To execute RunModel, the working directory must contain the necessary files (i.e. model_script,
input_template, and output_script) along with any other files required for model evaluation. These may include,
among other things, compiled executable files for third-party software that runs locally. There is an option to specify
a model directory (model_dir) as an input to RunModel, which creates a new directory whose name is given by
appending a timestamp corresponding to the time of executing the model to model_dir. All files in the working
directory are copied to the newly created model directory as illustrated below, and this directory becomes the working
directory for executing the model. The default model directory is model_dir='Model_Runs'.
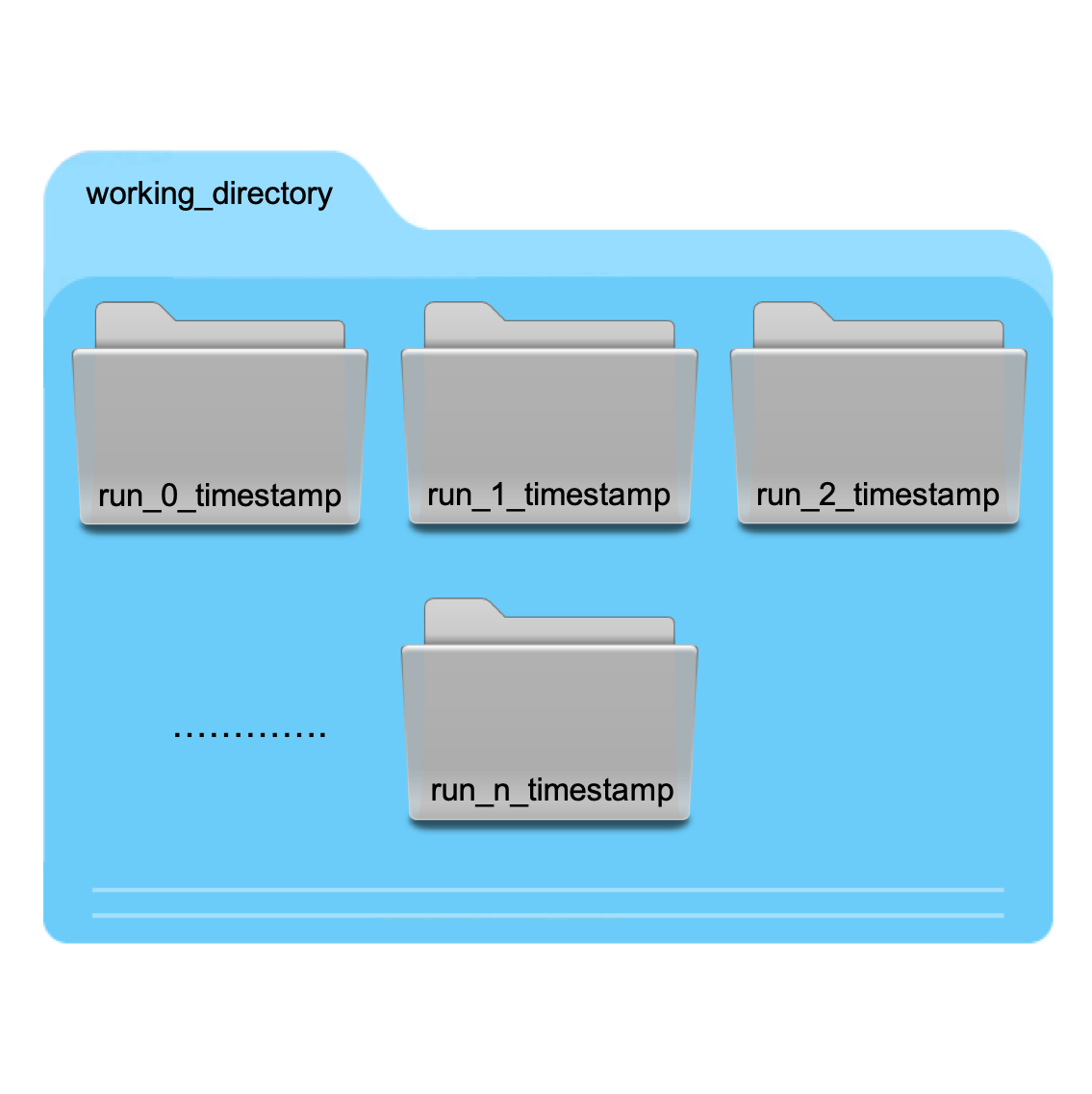
To avoid cluttering the working directory with outputs, RunModel creates a directory for each execution of the
model and saves the output generated during the model execution within the corresponding directory. RunModel
generates the directory name for the sample as run_n, where n is the python index of the run and timestamp
corresponds to the time at the beginning of the first simulation of the parallel job. This is illustrated in the figure below.
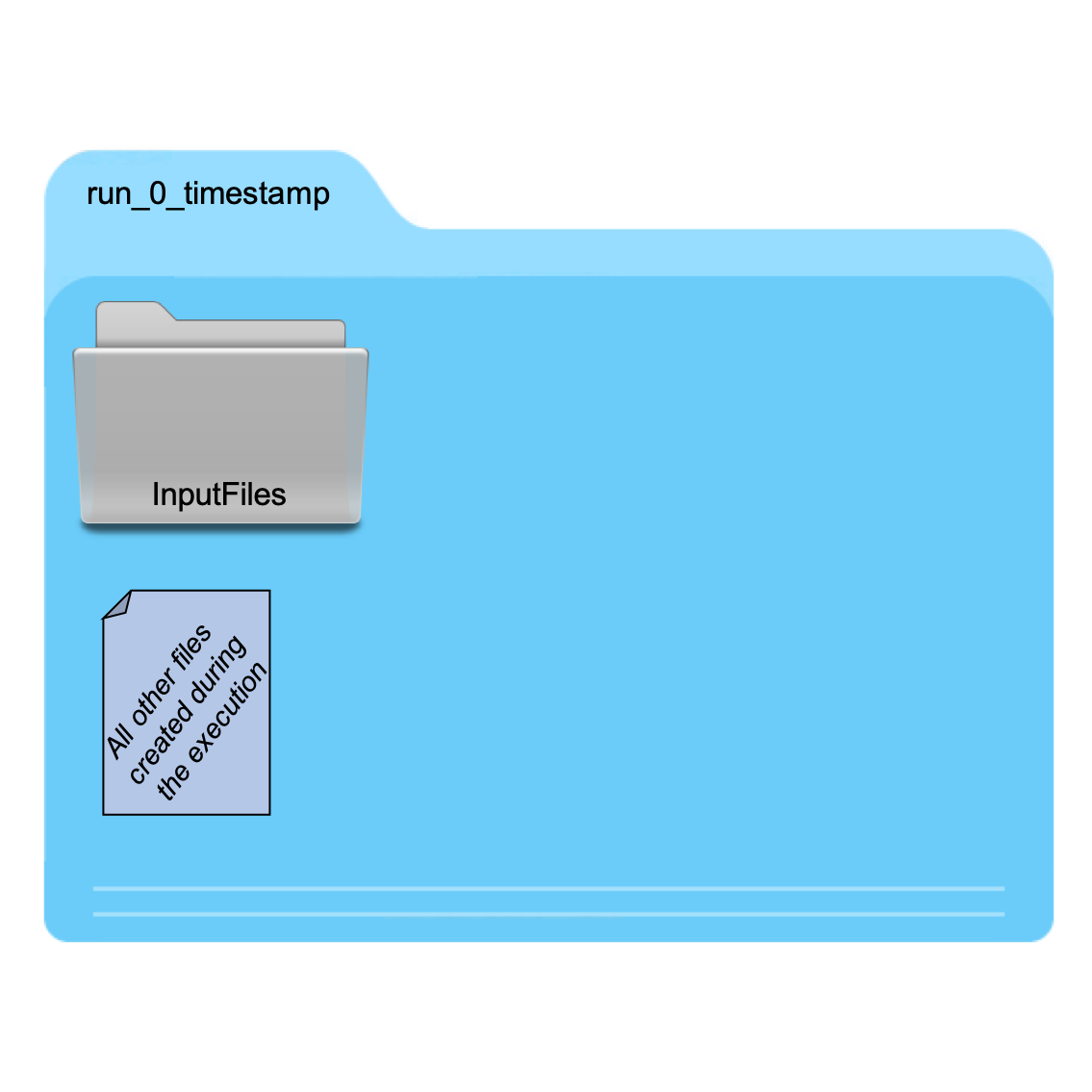
Within the working directory for each run, RunModel creates a new directory InputFiles and deposits the input
files generated in Step 1 above into this directory. The user’s model_script must retrieve the relevant input file
during the model execution. During model execution, RunModel first copies all the files in the working
directory to the directory for each sample, executes the model, and then deletes all the files copied into this
directory from the working directory. Any output generated either during model execution or during output processing
remains in this directory, as does the InputFiles directory. This is illustrated in the figure below.
Files & Scripts Used by RunModel
As discussed in the sections above and illustrated in the examples, the RunModel class utilizes a python
script to execute the computational model (model_script), a python script to extract the output (output_script)
and a template input file (input_template). This section is intended to provide a closer look at each of these
files, their structure, and when/if they are required.
model_script
model_script is the user-defined Python script that runs the computational model. It can be employed in two
different ways depending on the type of model being executed.
Python Model: For a python model, the
model_scriptis directly imported into the working python environment.
The model_script must have an object (either a class object or a function object) defined within it, and specified
in RunModel by model_object_name, that contains the computational model itself. The samples passed to
RunModel and any additional keyword arguments are passed as inputs to the model object. Examples for how the
Python model may be structured are provided below.
Example: Model object as a class:
class ModelClass:
def __init__(self, input=one_sample, **kwargs):
# Execute the model using the input and get the output
self.qoi = output
Example: Model object as a function:
def model_function(input=one_sample, **kwargs):
# Execute the model using the input and get the output
return output
Third-Party Software Model: When running a third-party model,
RunModeldoes not importmodel_script.
- Instead,
RunModelcalls the model script through the command line as
$ python3 model_script(sample_index)using the Python
firemodule. Notice the only variable passed intomodel_scriptis thesample_index. This is because the samples are being passed through the input files (viainput_template, see below). For example, if the model object is passed the sample index n, it should then execute the model using the input file whose name is input_n.inp, whereinput_template = 'input.inp'.In the
model_scriptfile, it is necessary to build the executable commands into a function so that the sample index can be passed into the script – allowing the script to recognize which input file to use. Because the executable commands must be built into a function, it is necessary to call this function using the Pythonfiremodule as illustrated in the first two lines ofmatlab_model_script.pybelow.Also note that the
model_scriptmust index the name of the output file for subsequent postprocessing through theoutput_scriptdiscussed below.An example of the the
model_scriptcorresponding to execution of a Matlab model withinput_template = 'matlab_model.m', as illustrated in theinput_templateexample, is given below.
matlab_model_script.py
import os
import fire
if __name__ == '__main__':
fire.Fire(model)
def model(sample_index):
# Copy the input file into the cwd
command1 = "cp ./InputFiles/matlab_model_" + str(index+1) +
".m ."
command2 = "matlab -nosplash -nojvm -nodisplay -nodesktop -r
'run matlab_model_" + str(sample_index + 1) + ".m;
exit'"
# Rename the output file
command3 = "mv y.txt y_" + str(sample_index+1) + ".txt"
os.system(command1)
os.system(command2)
os.system(command3)
Examples of the model_script are given in the example folder on the UQpy repository as described in the
Section entitled Examples & Template Files.
input_template
input_template is a user-defined file that is is used only when executing a third-party software model with
RunModel. As the name implies, input_template serves as a template of the model input file from which
individual, run-specific model input files will be generated for each model evaluation. The model input file is
typically an ASCII text-based file that defines all parameters (e.g. geometry, material properties, boundary conditions,
loading, etc.) of the computational model. For each individual model evaluation, RunModel will modify this template
through place-holder variables following a UQpy specific convention. This convention is described herein. The
place-holder variables are replaced with numerical values from the samples passed as input to RunModel.
UQpy place-holder variable convention:
Place-holders are defined by using
< >around the variable name within the template input file.Variable names are specified within
RunModelusing thevar_namesinput.RunModelscans the text within the input template looking for place-holders with each variable name and places the corresponding sample values in that location in the model input file.If
var_names = None,RunModelassigns default variable names as x0, x1, x2, …, xn.Standard python indexing is supported when using place-holders.
For example, if var1 is a numpy array, then it is possible to specify
<var1[i][j]>, which will then place the corresponding i,j component of var1 at that location. If var1 is an array and no index is specified within the place-holder then the entire contents of var1 are written in a delimited format at that location in the input file, where the user can prescribe the delimiter using theseparatorinput.In order to properly build the input files for each model evaluation, it is critical that the
samplespassed intoRunModeladhere to the following simple rules:The first dimension of
samplesmust correspond to the number of samples at which the model will be evaluated.The second dimension of
samplesmust correspond to the number of variables being passed into each model evaluation. Note that variables do not need to be scalars. Variables can be scalars, vectors, matrices, or tensors. When writing vectors, matrices, and tensors, they are first flattened and written in delimited form.
Examples of the template_input are given in the example folder on the UQpy repository as described in the Section entitled Examples & Template Files.
output_script
The output_script is an optional user-defined Python script for post-processing model output. Specifically, it is
used to extract user-specified quantities of interest from third-party model output files and return them to
RunModel. UQpy imports the output_script and executes the object defined by
output_object_name. The output object should accept only the sample index as input. If the model object is a Class,
the quantity of interest must be stored as an attribute of the class called qoi. If it is a function, it must return
the quantity of interest after execution. Examples for how the output object may be structured are provided below.
Example: Output object as a class:
class OutputClass:
def __init__(self, input=sample_index):
# Postprocess the output files corresponding to the
# sample number and extract the quantity of interest
self.qoi = output
Example: Output object as a function:
def output_function(input=sample_index):
# Postprocess the output files corresponding to the sample
# number and extract the quantity of interest
return output
Executable Software
Often, the working directory will contain an executable software program. This is often the case for custom software and for software that does not lie in the user’s path.
Examples & Template Files
In the example folder, several examples are provided to run both python models and third-party software models in
serial and in parallel. These examples are briefly summarized below. Note that the problems presented are for
demonstration purposes and are not necessarily intended to be used for accurate modeling of the problems described.
Instead, the primary intention is to show the files that are used in running models with each software package - in
particular the model_script and input_template.
Python Models
Several simple mathematical python models are provided in a Jupyter script entitled
Python_Model_with_Heterogeneous_Data.ipynb. These examples illustrate how to write functions and classes that execute
models in python using RunModel. The notebook executes models in serial and in parallel. The models themselves are
provided in the python file python_model.py.
PythonModel Class
- class PythonModel(model_script, model_object_name, var_names=None, delete_files=False, **model_object_name_kwargs)[source]
- Parameters:
model_script (
str) –The filename (with .py extension) of the Python script which contains commands to execute the model.
The named file must be present in the current working directory from which
RunModelis called.model_object_name (
str) –In the Python workflow, model_object_name specifies the name of the function or class within model_script’ that executes the model. If there is only one function or class in the `model_script, then it is not necessary to specify the model_object_name. If there are multiple objects within the model_script, then model_object_name must be specified.
model_object_name is not used in the third-party software model workflow.
var_names (
Optional[list[str]]) –A list containing the names of the variables present in input_template.
If input template is provided and var_names is not passed, i.e. if
var_names=None, then the default variable names x0, x1, x2,…, xn are created and used byRunModel, where n is the number of variables (n_vars).The number of variables is equal to the second dimension of samples (i.e.
n_vars=len(samples[0])).var_names is not used in the Python model workflow.
delete_files (
bool) –Specifies whether or not to delete individual run output files after model execution and output processing.
If delete_files = True,
RunModelwill remove all run_i… directories in the model_dir.model_object_name_kwargs – Additional inputs to the Python object specified by model_object_name in the Python model workflow.
Third-Party Models
RunModel can be used to execute nearly any third-party model. In the example folder, we provide files for
the execution of several commonly-used engineering software packages.
ThirdPartyModel Class
- class ThirdPartyModel(var_names, input_template, model_script, output_script=None, model_object_name=None, output_object_name=None, fmt=None, separator=', ', delete_files=False, model_dir='Model_Runs')[source]
- Parameters:
A list containing the names of the variables present in input_template.
If input template is provided and var_names is not passed, i.e. if
var_names=None, then the default variable names x0, x1, x2,…, xn are created and used byRunModel, where n is the number of variables (n_vars).The number of variables is equal to the second dimension of samples (i.e.
n_vars=len(samples[0])).var_names is not used in the Python model workflow.
input_template (
str) –The name of the template input file that will be used to generate input files for each run of the model. When operating
RunModelwith a third-party software model,input_templatemust be specified.The named file must be present in the current working directory from which
RunModelis called.model_script (
str) –The filename (with .py extension) of the Python script which contains commands to execute the model.
The named file must be present in the current working directory from which
RunModelis called.model_object_name (
Optional[str]) – In the Python workflow, model_object_name specifies the name of the function or class within model_script’ that executes the model. If there is only one function or class in the `model_script, then it is not necessary to specify the model_object_name. If there are multiple objects within the model_script, then model_object_name must be specified.output_script (
Optional[str]) –The filename of the Python script that contains the commands to process the output from third-party software model evaluation. output_script is used to extract quantities of interest from model output files and return the quantities of interest to
RunModelfor subsequentUQpyprocessing (e.g. for adaptive methods that utilize the results of previous simulations to initialize new simulations).If, in the third-party software model workflow,
output_script = None(the default), then theqoi_listattribute is empty and postprocessing must be handled outside ofUQpy.If used, the named file must be present in the current working directory from which
RunModelis called.output_script is not used in the Python model workflow. In the Python model workflow, all model postprocessing is handled directly within model_script.
output_object_name (
Optional[str]) –The name of the function or class within output_script that is used to collect and process the output values from third-party software model output files. If the object is a class, the output must be saved as an attribute called
qoi. If it is a function, it should return the output quantity of interest.If there is only one function or only one class in output_script, then it is not necessary to specify output_object_name. If there are multiple objects in output_script, then output_object_name must be specified.
If the template_input requires variables to be written in specific format, this format can be specified here.
Format specification follows standard Python conventions for the str.format() command described at: https://docs.python.org/3/library/stdtypes.html#str.format. For additional details, see the Format String Syntax description at: https://docs.python.org/3/library/string.html#formatstrings.
For example, ls-dyna .k files require each card is to be exactly 10 characters. The following format string syntax can be used, “{:>10.4f}”.
separator (
str) – A string used to delimit values when printing arrays to the template_input.delete_files (
bool) –Specifies whether or not to delete individual run output files after model execution and output processing.
If delete_files = True,
RunModelwill remove all run_i… directories in the model_dir.model_dir (
str) – Specifies the name of the sub-directory from which the model will be executed and to which output files will be saved. A new directory is created byRunModelwithin the current directory whose name is model_dir appended with a timestamp.
Abaqus Model
Code is provided for execution of 100 Monte Carlo samples of two random variables for the analysis of a beam subject to
thermo-mechanical loading under fire conditions. The example is described in [17]. The analysis is set up to run on a
HPC cluster (specifically the Maryland Advanced Research Computing Center, MARCC) using the SLURM scheduler from the
shell script run_sfe_example.sh. The model executes 100 finite element calculations using the Abacus software over a
total of 25 cores on a single compute node with each calculation using 1 core. The requisite RunModel files
are the following:
model_script = 'abaqus_fire_analysis.py'input_template = 'abaqus_input.py'output_script = 'extract_abaqus_output.py'
Also necessary is the Abaqus postprocessing script abaqus_output_script.py.
Of particular note is the input_template. For Abaqus, the input_template may be an Abaqus input (.inp) file or
an Abaqus python model file (.py). In this case, we directly input the variables in the Python model generation file.
LS-DYNA Model
Code is provided for execution of arbitrary Lagrangian-Eulerian finite element calculations of a small material element with random spherical voids. Two examples are provided, entitled single_job and multi-job.
The single_job calculation executes a single finite element calculation on an HPC cluster (specifically MARCC) using
the SLURM scheduler over 2 nodes and using a total of 48 cores. The requisite RunModel files are the following:
model_script = 'dyna_script'input_template = 'dyna_input.k'
No output_script is used for postprocessing.
The multi_job calculation executes 12 finite element calculations on an HPC cluster (specifically MARCC) using the
SLURM scheduler over 3 nodes with each calculation using 12 cores. The requisite RunModel files are the
following:
model_script = 'dyna_script'input_template = 'dyna_input.k'
No output_script is used for postprocessing.
Note that in both models, LS-DYNA requires that the text-based input cards each possess 10 characters. Therefore, it is
necessary to set fmt='{:>10.4f}' in ``RunModel to write the variables to the input files correctly.
Note that these calculations are for demonstration purposes only and are not intended to be physically representative of any material system. Moreover, to make them computationally inexpensive the mesh is severely under-resolved.
Matlab Model
Several simple mathematical Matlab models are provided in a Jupyter script entitled
Third-Party_Model_with_Heterogeneous_Data.ipynb. These examples illustrate how to write variables to a matlab model
(.m) file using RunModel. Several template_input and model_script files are provided. The notebook
executes models in serial and in parallel.
These examples do not use HPC resources.
OpenSees Model
The model considers a six-story building with 2 bays in the X-direction and 2 bays in the y-directions. The model has reinforced-concrete rectangular columns and beams. A static pushover analysis is performed. At each story the concrete’s yield strength fc ~Uniform (15000, 25000), the reinforcement steel’s Young’s modulus Es ~Uniform (2.0e8, 0.5e8) and yield strength Fy ~Uniform (450000, 530000) are considered random variables. Thus, the problem has a total of 6*3 = 18 random variables. The horizontal displacement (x-axis) of the top floor is monitored.
Five Monte Carlo samples are generated and the model is evaluated in parallel over five CPUs on an HPC cluster
(specifically MARCC) using the SLURM scheduler. The requisite RunModel files are the following:
model_script = opensees_model.pyinput_template = import_variables.tcloutput_script = process_opensees_output.py
The other necessary files are the following:
columndimensions.tcl
RCsection.tcl
run_opensees_UQpy.py
run_OpenSees.sh
test.tcl
Note that this example is not intended to represent the accurate pushover analysis a real structure. It is for
UQpy illustration purposes only.
RunModel Class
- class RunModel(model, samples=None, ntasks=1, cores_per_task=1, nodes=1, resume=False, run_type='LOCAL', cluster_script=None)[source]
Run a computational model at specified sample points.
This class is the interface between
UQpyand computational models. The model is called in a Python script whose name must be passed as one the arguments to theRunModelcall. If the model is in Python,UQpyimport the model and executes it directly. If the model is not in Python,RunModelmust be provided the name of a template input file, the name of the Python script that runs the model, and an (optional) output Python script.- Parameters:
samples (
Union[list,ndarray,None]) –Samples to be passed as inputs to the model. Regardless of data type, the first dimension of
samplesmust be equal to the number of samples at which to execute the model. That is,len(samples) = nsamples.Regardless of data type, the second dimension of
samplesmust be equal to the number of variables to to pass for each model evaluation. That is,len(samples[0]) = n_vars. Each variable need not be a scalar. Variables may be scalar, vector, matrix, or tensor type (i.e. float, list, or ndarray).If samples are not passed, a
RunModelobject will be instantiated that can be used later, with therun()method, to evaluate the model.Used in both python and third-party model execution.
ntasks (
int) –Number of tasks to be run in parallel. By default,
ntasks = 1and the models are executed serially.Setting ntasks equal to a positive integer greater than 1 will trigger the parallel workflow.
ntasks is used for both the Python and third-party model workflows.
RunModeluses GNU parallel to execute third-party models in parallel and the multiprocessing module to execute Python models in parallel.cores_per_task (
int) –Number of cores to be used by each task. In cases where a third-party model runs across multiple CPUs, this optional attribute allocates the necessary resources to each model evaluation.
cores_per_task is not used in the Python model workflow.
nodes (
int) – Number of nodes across which to distribute individual tasks on an HPC cluster in the third-party model workflow. If more than one compute node is necessary to execute individual runs in parallel, nodes must be specified.
-
samples:
ndarray Internally,
RunModelconverts the input samples into a numpy ndarray with at least two dimension where the first dimension of thenumpy.ndarraycorresponds to a single sample to be executed by the model.
-
qoi_list:
list A list containing the output quantities of interest
In the third-party model workflow, these output quantities of interest are extracted from the model output files by output_script.
In the Python model workflow, the returned quantity of interest from the model evaluations is stored as
qoi_list.This attribute is commonly used for adaptive algorithms that employ learning functions based on previous model evaluations.
-
n_existing_simulations:
int Number of pre-existing model evaluations, prior to a new
run()method call.If the
run()methods has previously been called and model evaluations performed, subsequent calls to therun()method will be appended to theRunModelobject.nexiststores the number of previously existing model evaluations.
- run(samples=None, append_samples=True)[source]
Execute a computational model at given sample values.
If samples are passed when defining the
RunModelobject, therun()method is called automatically.The
run()method may also be called directly after defining theRunModel()object.- Parameters:
samples (list) –
Samples to be passed as inputs to the model defined by the
RunModelobject.Regardless of data type, the first dimension of
samplesmust be equal to the number of samples at which to execute the model. That is,len(samples) = nsamples.Regardless of data type, the second dimension of
samplesmust be equal to the number of variables to to pass for each model evaluation. That is,len(samples[0]) = n_vars. Each variable need not be a scalar. Variables may be scalar, vector, matrix, or tensor type (i.e. float, list, or ndarray).Used in both python and third-party model execution.
append_samples (bool) –
Append over overwrite existing samples and model evaluations.
If
append_samples = False, all previous samples and the corresponding quantities of interest from their model evaluations are deleted.If
append_samples = True, samples and their resulting quantities of interest are appended to the existing ones.