MCMC
The goal of Markov Chain Monte Carlo is to draw samples from some probability distribution \(p(x)=\frac{\tilde{p}(x)}{Z}\), where \(\tilde{p}(x)\) is known but \(Z\) is hard to compute (this will often be the case when using Bayes’ theorem for instance). In order to do this, the theory of a Markov chain, a stochastic model that describes a sequence of states in which the probability of a state depends only on the previous state, is combined with a Monte Carlo simulation method, see e.g. ([27], [10]). More specifically, a Markov Chain is built and sampled from whose stationary distribution is the target distribution \(p(x)\). For instance, the Metropolis-Hastings (MH) algorithm goes as follows:
initialize with a seed sample \(x_{0}\)
- walk the chain: for \(k=0,...\) do:
sample candidate \(x^{\star} \sim Q(\cdot \vert x_{k})\) for a given Markov transition probability \(Q\)
accept candidate (set \(x_{k+1}=x^{\star}\)) with probability \(\alpha(x^{\star} \vert x_{k})\), otherwise propagate last sample \(x_{k+1}=x_{k}\).
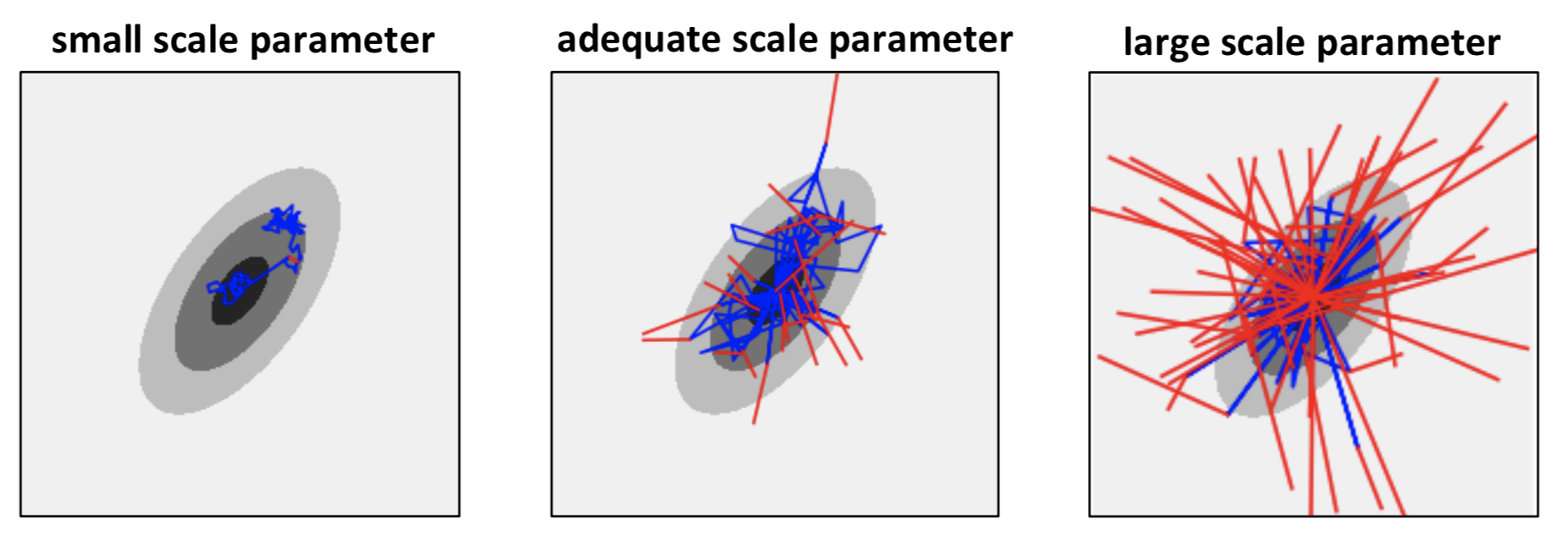
The transition probability \(Q\) is chosen by the user (see input proposal of the MH algorithm, and careful attention must be given to that choice as it plays a major role in the accuracy and efficiency of the algorithm. The following figure shows samples accepted (blue) and rejected (red) when trying to sample from a 2d Gaussian distribution using MH, for different scale parameters of the proposal distribution. If the scale is too small, the space is not well explored; if the scale is too large, many candidate samples will be rejected, yielding a very inefficient algorithm. As a rule of thumb, an acceptance rate of 10%-50% could be targeted.
Finally, samples from the target distribution will be generated only when the chain has converged to its stationary
distribution, after a so-called burn-in period. Thus the user would often reject the first few samples (see input
nburn). Also, the chain yields correlated samples; thus to obtain i.i.d. samples from the target distribution,
the user should keep only one out of n samples (see input jump). This means that the code will perform in total
burn_length + jump * N evaluations of the target pdf to yield N i.i.d. samples from the target distribution (for the MH
algorithm with a single chain).
The parent class for all MCMC algorithms is the MCMC class, which defines the inputs that are common to all
MCMC algorithms, along with the run() method that is being called to run the chain. Any given MCMC algorithm is a
child class of MCMC that overwrites the main run_one_iteration() method.
MCMC Class
Methods
- class MCMC(dimension=None, pdf_target=None, log_pdf_target=None, args_target=None, seed=None, burn_length=0, jump=1, n_chains=None, save_log_pdf=False, concatenate_chains=True, random_state=None)[source]
Generate samples from arbitrary user-specified probability density function using Markov Chain Monte Carlo.
This is the parent class for all MCMC algorithms. This parent class only provides the framework for MCMC and cannot be used directly for sampling. Sampling is done by calling the child class for the specific MCMC algorithm.
- Parameters:
dimension (
Optional[int]) – A scalar value defining the dimension of target density function. Either dimension and n_chains or seed must be provided.pdf_target (
Union[Callable,list[Callable],None]) –Target density function from which to draw random samples. Either pdf_target or log_pdf_target must be provided (the latter should be preferred for better numerical stability). If pdf_target is a callable, it refers to the joint pdf to sample from, it must take at least one input
x, which are the point(s) at which to evaluate the pdf. Within MCMC the pdf_target is evaluated as:p(x) = pdf_target(x, *args_target)wherexis a ndarray of shape(nsamples, dimension)and args_target are additional positional arguments that are provided to MCMC via its args_target input. Ifpdf_targetis a list of callables, it refers to independent marginals to sample from. The marginal in dimensionjis evaluated as:p_j(xj) = pdf_target[j](xj, *args_target[j])wherexis a ndarray of shape(nsamples, dimension)log_pdf_target (
Union[Callable,list[Callable],None]) – Logarithm of the target density function from which to draw random samples. Either pdf_target or log_pdf_target must be provided (the latter should be preferred for better numerical stability).args_target (
Optional[tuple]) – Positional arguments of the pdf / log-pdf target function. See pdf_targetseed (
Optional[list]) – Seed of the Markov chain(s), shape(nchains, dimension). Default:zeros(nchains, dimension). If seed is not provided, both nchains and dimension must be provided.burn_length (
int) – Length of burn-in - i.e., number of samples at the beginning of the chain to discard (note: no thinning during burn-in). Default is \(0\), no burn-in.jump (
int) – Thinning parameter, used to reduce correlation between samples. Settingjump=ncorresponds to skippingn-1states between accepted states of the chain. Default is \(1\) (no thinning).n_chains (
Optional[int]) – The number of Markov chains to generate. Either dimension and nchains or seed must be provided.save_log_pdf (
bool) – Boolean that indicates whether to save log-pdf values along with the samples. Default:Falseconcatenate_chains (
bool) – Boolean that indicates whether to concatenate the chains after a run, i.e., samples are stored as annumpy.ndarrayof shape(nsamples * nchains, dimension)ifTrue,(nsamples, nchains, dimension)ifFalse. Default:Truerandom_state (
Union[None,int,RandomState]) – Random seed used to initialize the pseudo-random number generator. Default isNone. If anintis provided, this sets the seed for an object ofnumpy.random.RandomState. Otherwise, the object itself can be passed directly.
- run(nsamples=None, nsamples_per_chain=None)[source]
Run the mcmc algorithm.
This function samples from the mcmc chains and appends samples to existing ones (if any). This method leverages the
run_one_iteration()method that is specific to each algorithm.- Parameters:
Either nsamples or nsamples_per_chain must be provided (not both). Not that if nsamples is not a multiple of n_chains, nsamples is set to the next largest integer that is a multiple of n_chains.
- run_one_iteration(current_state, current_log_pdf)[source]
Run one iteration of the mcmc algorithm, starting at current_state.
This method is over-written for each different mcmc algorithm. It must return the new state and associated log-pdf, which will be passed as inputs to the
run_one_iteration()method at the next iteration.- Parameters:
current_state (
ndarray) – Current state of the chain(s),numpy.ndarrayof shape(n_chains, dimension).current_log_pdf (
ndarray) – Log-pdf of the current state of the chain(s),numpy.ndarrayof shape(n_chains, ).
- Returns:
New state of the chain(s) and Log-pdf of the new state of the chain(s)
Attributes
-
MCMC.evaluate_log_target:
Callable It is a callable that evaluates the log-pdf of the target distribution at a given point x
-
MCMC.evaluate_log_target_marginals:
Callable It is a callable that evaluates the log-pdf of the target marginal distributions at a given point x
-
MCMC.samples:
ndarray Set of MCMC samples following the target distribution,
numpy.ndarrayof shape(nsamples * n_chains, dimension)or(nsamples, n_chains, dimension)(see input concatenate_chains).
-
MCMC.log_pdf_values:
ndarray Values of the log pdf for the accepted samples,
numpy.ndarrayof shape(n_chains * nsamples,)or(nsamples, n_chains)
Examples
List of MCMC algorithms
Adding New MCMC Algorithms
In order to add a new MCMC algorithm, a user must create a child class of MCMC(), and overwrite the
run_one_iteration() method that propagates all the chains forward one iteration. Such a new class may use any
number of additional inputs compared to the MCMC base class. The reader is encouraged to have a look at the
MetropolisHastings class and its code to better understand how a particular algorithm should fit the general framework.
A useful note is that the user has access to a number of useful attributes / utility methods as the algorithm proceeds, such as:
the attribute
evaluate_log_target()(and possiblyevaluate_log_target_marginals()if marginals were provided) is created at initialization. It is a callable that simply evaluates the log-pdf of the target distribution at a given point x. It can be called within the code of a new sampler aslog_pdf_value = self.evaluate_log_target(x).the
samples_numberandsamples_number_per_chainattributes indicate the number of samples that have been stored up to the current iteration (i.e., they are updated dynamically as the algorithm proceeds),the
samplesattribute contains all previously stored samples. Cautionary note:self.samplesalso contains trailing zeros, for samples yet to be stored, thus to access all previously stored samples at a given iteration the user must callself.samples[:self.nsamples_per_chain], which will return annumpy.ndarrayof size(self.nsamples_per_chain, self.nchains, self.dimension),the
log_pdf_valuesattribute contains all previously stored log target values. Same cautionary note as above,the
_update_acceptance_rate()method updates theacceptance_rateattribute of the sampler, given a (list of) boolean(s) indicating if the candidate state(s) were accepted at a given iteration,the
_check_methods_proposal()method checks whether a given proposal is adequate (i.e., hasrvs()andlog_pdf()/pdf()methods).